Have you ever wondered how a typical distributed system works under the hood? Are you looking for a pedagogical guide with complete implementations and tricks of the trade? Look no further and read my writing on the topic. We have implemented several foundational algorithms in Distributed Computing. After completing the first phase of this research, it became apparent that I have not ruled out the possibility of working full-time on these topics.
**Related Blogs**
+ [Authoring a book on Distributed Computing](https://kenluck2001.github.io/blog_post/authoring_a_new_book_on_distributed_computing.html)
+ [Book Launch on Distributed Computing](https://kenluck2001.github.io/blog_post/book_launch_published_a_free_technical_book_on_distributed_computing)
A few years ago, I was deficient in the low-level knowledge needed to build a large-scale distributed system without utilizing third-party packages. This motivated me to research this topic from scratch, and I subsequently became a better Software Engineer in the process. My initial foray into distributed systems began due to my participation in a Distributed Systems meetup, where I eventually became the organizer in Vancouver. Our study group utilized materials from the Distributed Systems course at [KTH](https://www.kth.se/en) Sweden. Our goal was mainly to gain intuition and theoretical knowledge on the subject. Luckily, I took the step further when I took the [Parallel, Concurrent, and Distributed Programming in Java Specialization](https://www.coursera.org/specializations/pcdp) in [Coursera](https://www.coursera.org/), where I saw [OpenMPI](https://en.wikipedia.org/wiki/Open_MPI) mentioned and knew it was the missing link in my dive into implementing low-level distributed algorithms.
As I started researching, I noticed a troubling trend in Distributed Systems research. This is because the most cutting-edge works in the field are performed in top research labs, advanced technical schools, and by seasoned open source contributors. Unfortunately, this status quo is unacceptable. Hence, I am motivated to invest in this research to distill this knowledge to a wider audience. Our focus is on delivering scientific content without diluting the content and maintaining world-class rigor. We are poised to create disruptive change by sharing knowledge hidden within plain sight. One axiom from the [Zen of Python](https://www.python.org/dev/peps/pep-0020/) posits that "practicality beats purity", so rather than pontificate on the state-of-the-art distributed algorithm, we have taken the approach of solidifying the fundamentals.
##### **Notes:**
+ This work is based on non-proprietary content that is unrelated to my employer. This is part of my hobby, and I used only publicly-sourced information. The blog summarizes the first phase of my two-phased research on low-level Distributed Systems. The second phase of my research will be covered in my [upcoming textbook](https://kenluck2001.github.io/blog_post/authoring_a_new_book_on_distributed_computing.html).
+ Every source code is the original work of the author.
+ Unlike other intellectual works, some of our references will be secondary sources. This decision is taken to keep our references within a reasonable scope.
**Full disclosure:** I had implemented portions of the KTH Distributed system course that ran on [Edx](https://www.edx.org/) taught by Professor Haridi. I am grateful as it was my first exposure to Distributed Computing. I would also include some of his slides (Single-Value Paxos, Sequence Paxos) in this blog with full attribution.
##### Terminologies
+ Quorum: a set of the majority of correct processes
+ nodes, replicas, and processes that will be used interchangeably and have the same meaning in the context of this blog.
+ Model: abstraction of the dynamics of a system
+ Reliable broadcast: a message sent to a group of processes is delivered by all or none.
+ Atomic commit: processes commit or abort a transaction.
+ Transaction: These are a series of operations that can be completed without interruptions. If any operation fails, the entire operation is aborted, e.g. 2-phase commit, 3-phase commit.
+ Multicast: A source sends to multiple destinations and works in LAN and WAN.
+ Broadcast: A single source sends to multiple destinations and works in LAN.
+ Computational graph: abstraction of order sequence of processes.
+ Optimistic concurrency is a viable strategy when you expect low contention. Computation on a shared object is expensive due to the overhead of locks.
# **Table of Contents**
+ [Algorithm implementations](#algorithm-implementations)
+ [Network programming](#network-programming)
+ [Parallel programming](#parallel-programming)
+ [OpenMPI](#openmpi)
+ [Distributed System](#distributed-system)
- [Theoretical foundations (two-general problem, impossibility proof)](#theoretical-foundations)
- [Logical clocks](#logical-clocks)
- [Paxos (Single Value Paxos, Sequence Paxos)](#paxos)
- [Failure detector](#failure-detector)
- [Leader election](#leader-election)
- [Raft](#raft)
- [Implementation Philosophy for Source Code](#implementation)
- [Anti-entropy (CRDT, Merkle tree)](#anti-entropy)
- [Case studies](#case-studies)
+ [Distributed shared primitives](#distributed-shared-primitive)
+ [Distributed hashmap (key-value store using Lamport clock)](#distributed-hashmap)
+ [Practical considerations](#practical-considerations)
+ [Evaluation metrics](#evaluation-metrics)
+ [Exercises for the readers](#exercises)
+ [Future Work](#future-work)
+ [Acknowledgements](#acknowledgments)
+ [Conclusion](#conclusion)
+ [References](#references)
# **Algorithm Implementations**
My source code was tested with the following specification:
| Setup | Version |
| :--- | ---: |
| Operating system | Ubuntu 16.04.6 LTS |
| GCC | 5.4.0 20160609 |
| OpenMPI | 1.10.2 |
Here is my list of implemented Distributed Algorithms with [associated source codes](https://github.com/kenluck2001/DistributedSystemReseach/tree/master/blog). They include:
| S/N | Algorithms | Source Codes |
| :--- | :----: | ---: |
| 1 | Logical clock |[vector2.c](https://github.com/kenluck2001/DistributedSystemReseach/blob/master/blog/vector2.c), [lamport1.c](https://github.com/kenluck2001/DistributedSystemReseach/blob/master/blog/lamport1.c) |
| 2 | Paxos |[single-paxos3.c](https://github.com/kenluck2001/DistributedSystemReseach/blob/master/blog/single-paxos3.c) |
| 3 | Sequence Paxos |[sequence-paxos4.c](https://github.com/kenluck2001/DistributedSystemReseach/blob/master/blog/sequence-paxos4.c) |
| 4 | Failure detector |[failure-detector2.c](https://github.com/kenluck2001/DistributedSystemReseach/blob/master/blog/failure-detector2.c) |
| 5 | Leader election |[leader-election2.c](https://github.com/kenluck2001/DistributedSystemReseach/blob/master/blog/leader-election2.c) |
| 6 | Raft |[Raft algorithm](#raft) |
| 7 | Distributed shared primitives |[shared primitive](#distributed-shared-primitive) |
| 8 | Distributed hashmap |[lamport1-majority-voting8.c](https://github.com/kenluck2001/DistributedSystemReseach/blob/master/blog/lamport1-majority-voting8.c) |
Some of my implementations are tracked in my [playground](https://github.com/kenluck2001/DistributedSystemReseach/tree/master/playground) where you can follow my thought process during incremental development. Some of the implementations in [playground](https://github.com/kenluck2001/DistributedSystemReseach/tree/master/playground) have faulty solutions due to incorrect assumptions. However, the [implementations](https://github.com/kenluck2001/DistributedSystemReseach/tree/master/blog) referenced directly in this blog are verified by the author and are free of obvious errors.
We had settled on OpenMPI as the underlying library to provide low-level functionality. In comparison to Remote Procedural Call that blurs the message-passing paradigm by passing arguments as messages, MPI provides a structured way for implementing our Distributed Algorithms. Hence, all implementations would strictly use [OpenMPI](https://en.wikipedia.org/wiki/Open_MPI) in [C](https://en.wikipedia.org/wiki/ANSI_C). Event-based programming based on message passing can serve as a convenient abstraction for building Distributed Systems. Hence, we are using this approach for all of our implementations.
As a matter of pedagogy, we have excluded tracing and invariant proofs, even though these concepts are essential to Distributed System's scholarship. As a result, we anticipate that users will learn by doing instead of getting bogged down in mathematics.ing bogged down in mathematics. We abandoned the idea of splitting this content across several blogs because I am not a fan of fragmented content. It is better to have a comprehensive resource in one place.
# **Network Programming**
The socket is the basic file for networking. Let us recap the Unix philosophy that everything is a file. Socket() returns a descriptor. Sending a message over a network becomes analogous to writing to a file stream while receiving the message is comparable to reading a file stream. However, we are communicating over a network in a channel.
There are two basic sockets, [[4]]()
+ Stream socket (SOCK_STREAM)
+ Datagram socket (SOCK_DGRAM)
Most local networks will use an internal IP address, while the Internet-facing gateways make use of an external IP address, with NAT doing the conversion from Internet IP to internal IP.
When communicating between nodes on Distributed Systems, there is a need for a channel to provide a medium for message transfer between nodes. Here are the kinds of channels [[2]]() in use in Distributed Systems which include:
+ Fair loss link
+ Stubborn link
+ Perfect link
+ Logged perfect link
They have specific characteristics that are unique to each of them (links).
For more information on the subject, please read the following:
+ UNIX Network Programming Volume 1, Third Edition: The Sockets Networking API By W. Richard Stevens, Bill Fenner, Andrew M. Rudoff
+ Beej's Guide to Network Programming Using Internet Sockets by Brian Hall
# **Parallel Programming**
In Unix, fork() creates a new process. A parent process creates a new child process. The parent process must wait for the child process to exit. This waiting allows the child process to exit.
This can be problematic if the child is defunct and the parent process ignored waiting.
In some systems, init destroys the defunct process.
The child process becomes a zombie until the parent process waits or the parent ignores waiting using SIGCHLD [[3, 4]]().
Ignoring waiting for the child process to exit on the parent process
```
int main()
{
signal(SIGCHLD, SIG_IGN); //don't wait
fork();
}
```
process/thread is a core foundation of building Distributed computing [[6, 7]]()
+ Processes are units of work distribution.
+ Threads: unit of concurrency
There are significant challenges with parallel programming, such as data sharing, coordination, deadlock, lock granularity, and others [[6, 7]]().
It is possible to have multiple threads in a process. Here are some benefits [[6, 7]]():
+ Memory/resource efficiency due to sharing
+ Responsive (no network delays)
+ Performance (increased throughput)
note: if the process blocks, every internal thread blocks as well.
Another combination is to have multiple processes in a node. Here are some benefits [[6, 7]]():
+ Responsive (JVM delays)
+ Scalability
+ Availability / fault-tolerance
There are different forms of parallelism (task, functional, loop, data-flow) [[6]]().
Java has the popular fork-join framework based on the divide-and-conquer paradigm. This is useful if your problem can be decomposed in the structure [[6]]().
When using threads or processes, it is ideal to find the optimal number of threads or processes to prevent reduced performance due to degradation increased load due to process isolation, and communication costs for sharing information between processes.
[Promises and futures](https://en.wikipedia.org/wiki/Futures_and_promises) are a popular form of parallelism where we just make a differed call while performing a function and offload another task that is disjoint to be done in parallel and join on the result from the main thread.
Guaranteeing reproducibility can be a desirable goal. Quasi-randomness may be reasonable in some contexts. The parallel program can have the following characteristics to address this behavior [[6]]():
Functional determinism: the same input gives the same output on the same output for the same function.
Structural determinism: any repeat of the parallel program yields the same computational graph.
Let's say that your process is handling permutation-invariant data e.g unsorted data. We only need functional dependency and not structural determinism. This can provide clever shortcuts to optimize your program.
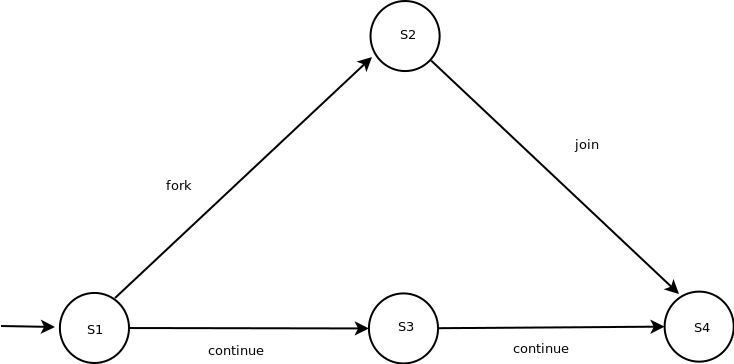
+ Each node is a sequential/sub-computation step
+ Each edge is an ordering constraint
Without a fork or join operation, we have a straight line between the start to finish nodes.
In our example, S2, and S3 run in parallel.
Metric performance
+ work: sum of execution times across every node
+ span: length of the longest path (critical path length)
For fork-join programs, the edge can be
+ Continue edge: capture sequencing of steps within a task.
+ Fork edge: connect fork operation to the first step of the child task.
Ideal parallelism, $ip = work/span$, for a sequential program, the ideal parallelism is 1. Computation graph is required [[6]]().
Unfortunately, we don't always have a computation graph. We can use [Amdahl's law](https://en.wikipedia.org/wiki/Amdahl%27s_law) which is that computation of a threaded program is restricted by sequential computation in the collection of processes [[6, 7]]().
There are also alternatives like share-nothing architecture (using message passing paradigm) e.g actor, distributed actor which makes use of message passing. There are also non-blocking approaches using getAndAdd() and compareAndSet [[6]]().
## Properties of a parallel program [[6]]()
+ Safety (not bad ever happens)
+ Liveness (something good eventually happens)
Let us use the analogy of a traffic stop
+ Safety: vehicles can only move in one direction at a time.
+ Liveness: even if there is traffic, every vehicle will have a certainty to leave the junction.
## Process Communication
Fine-tuning control of computer programs by mutual exclusion and synchronization. Let us define these two concepts.
Mutual exclusion occurs when two or more events do not occurt the same time. e.g. event, A precedes event, B.
Synchronization is guaranteeing the order of access of multiple threads to a shared resource. Synchronization outside a computer can be verified in real life by a clock. However, doing computer synchronization without a clock is a challenge, as there are also issues with the accuracy of clocks due to drifts. It is possible to do this using computational graphs, especially in a parallel program. It is easy to know the order of execution within a process, but it is challenging to ascertain the order of execution in a threaded program.
Synchronization is achievable by signaling or instructing the other party to wait until a condition is reached. There is a traditional synchronization issue in the literature that has wide applicability. They include producer-consumer with multiple variants, reader-writer problem, starvation problem (bounded wait on semaphore), and dining philosopher problem [[3, 5, 6]]().
The barrier is a construct that can build many threads and releases every blocked thread on receipt of the last on [[5]](). This is commonly known as a phaser in Java. MPI uses them extensively foreating collective operations. It can also be used for pipelining [[3, 5, 6]]().
A comprehensive book on interprocess communication is Beej's Guide to Unix IPC by Brian Hall. There are multiple venues for sharing information between processes in Unix.
+ Signal: A way of doing process communication. One process raises a signal and another process delivers it to the destination handler to effect a custom callback. I am not sure if it is thread-safe or even interrupt-safe.
+ Pipe: This is the simplest form of process communication. A process, writing to one end of a pipe and reading from the other end of the pipe. There are many variations, such as FIFO (named pipe).
+ Message queue (similar to msgsnd(), msgrcv()); see [usage](https://www.tutorialspoint.com/inter_process_communication/inter_process_communication_message_queues.htm).
+ Semaphore: At initialization, a semaphore is set to any value by the user. This is the number of threads that can pass through the critical section before blocking. Threads can increment or decrement the value of the semaphore, which cannot be read outside the semaphore construct. If the value of the semaphore turns negative, every thread will block unless it increments the value of the semaphore > 1. Most semaphore is not atomic, and race conditions may happen if multiple threads are accessing the resource at the same time.
One way to solve the issue is allowing a single init process that creates the semaphore before the main process begins to run. The main process accesses the semaphore, but cannot create or destroy it. There are similarities to restricting access using a lock, permissions e.t.c
+ Shared memory segments: A process writes to a memory segment and another process reads from the same segments. Coordinated access to the segment still has to be done using locks, semaphores e.g shmget(), shmat().
# **OpenMPI**
This is the implementation of a message-passing paradigm for the exchange of information between processes. OpenMPI [[8, 9, 10, 11]]() is used in rendering farms, high-performance computing, and Scientific computing. For example, [Curie](http://www-hpc.cea.fr/en/complexe/tgcc-curie.htm), a French supercomputer, makes extensive use of MPI. One of the most helpful materials to learn MPI on the Internet is on [Coding Game](https://www.codingame.com/playgrounds/349/introduction-to-mpi/introduction-to-distributed-computing).
The number of processes (size) is set at the point of setup of the MPI communicator. However, it is possible to make adjustments using clever process group management.
Every process has a rank (0, size-1).
+ mpi_bcast: all processes must wait until all processes have reached the same collective.
+ mpi has optimized the implementation of distributed operations.
Two types of communication are in use:
+ Point-to-point: two processes in communication.
+ Collective: every process is communicating together
point-to-point
+ send: move data from one process to another process.
+ recv: accept data that was sent to the process by other processes.
Collective operation
+ broadcast: one process sends a message to a group of processes.
+ reduction: one process gets data from every other process and applies transformation (sum, minimum, maximum).
+ scatter: a single process partitions the data and sends each chunk to every other process, e.g. MPI_Scatter.
+ gather a single process assemblies data from different processes in a buffer, e.g. MPI_Gather. MPI_AllGather is designed to gather and scatter the results from every process.
There are synchronization primitives like locks, barrier
## One-sided Communication
MPI allows for remote memory access (RMA). Here are some commands which include:
+ MPI_WIN_create()
+ MPI_WIN_allocate()
+ MPI_GET()
+ MPI_PUT()
+ MPI_Accumulate()
+ MPI_Win_free()
Unlike the two-sided communication model, which requires a sender and receiver where the sender transfers data to the receiver. However, in a one-sided communication model, a process can directly access another process's memory space address. Only one process can communicate directly without data transfer with minimum CPU intervention. There is a caveat where the ordering of RMA cannot be safely guaranteed [[10, 11]]().
In our implementation of the distributed shared primitive, we made extensive use of one-sided communication. RMA is non-blocking, but we are using it in a blocking mode by using locks. In our logic, perhaps doing an epoch with MPI_Win_fence would be better. Otherwise, we may lose some of the non-blocking advantages. MPI_Compare_and_swap may be a better alternative [[10, 11]]().
If you make a one-sided communication in place of the default two-sided communication, then how do you receive ACKS (receipt)?
Here is an example of an epoch
```
MPI_Win_fence // start of epoch
.
.
.
MPI_Win_fence // end of epoch
```
Is using a fence, better than using locks on the level of concurrency granularity?
Hints, MPI_Win_fence is a collective using ideas from barriers.
### Best Practices
+ No user-defined operation in MPI_Accumulate.
+ Ensure local completion before accessing the buffer in an epoch.
+ It is impossible to mix MPI_GET, MPI_PUT, and MPI_Accumulate in a single epoch
### Benefits
+ It can help to reduce synchronization.
+ It minimizes data movement (exclude buffering).
# **Distributed Systems**
Distributed System [[6, 7]]() is a set of nodes (devices) that are connected by a link and operate as a single system. Each device works locally independently but appears like a unified global device providing the "single view illusion" e.g Internet, edge computing, mobile, sensor network.
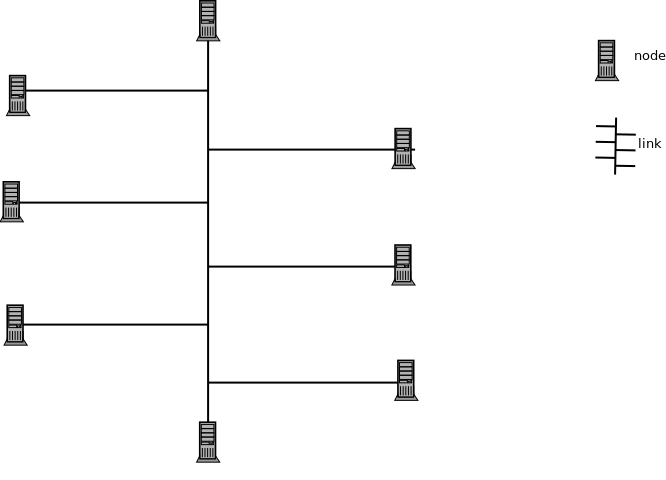
The benefits of using the Distributed system can include:
+ Faulty tolerance (reliability)
+ Scalability
+ Load distribution
There is a misconception that because we have a Distributed system, it must be scalable. This is not always the case, however, in horizontal scaling when communication cost is low and the task is parallelizable and can be distributed, then performance gains are possible. The challenges can include partial failures (network/node failure) and concurrency.
The ideal Distributed System is to provide maximum throughput with acceptable latency.
[CAP theorem](https://en.wikipedia.org/wiki/CAP_theorem) (only 2 can be satisfied) is an acronym used to describe a distributed System.
+ C: consistency (the last read was the previous write)
+ A: availability (data is ready for reads)
+ P: partition tolerance (handle network interruptions)
Distributed Systems can be AP (availability, partition tolerance) or CP (consistency, partition tolerance). The centralized system is AC (availability, consistency) because it does not tolerate network failures.
[Peter Deutsh made the list of fallacies connected to distributedistributed computing](https://en.wikipedia.org/wiki/Fallacies_of_distributed_computing).
+ Reliable network (network has some failures, always plan for retries and acks)
+ No latency (do consider the transportation time for packets in the network)
+ Infinite bandwidth (bandwidth of the network is limited, so chunk the packet size as appropriate)
+ Secure network (do consider the security of your network e.g. private or private network)
+ Fixed network topology
+ Existing administrator (there is no one as administrator, the system must be reasonably self-healing)
+ Zero transport cost (similar to "no latency", always expect some delays due to transport)
+ Homogenous network (expect that network partitions may exit)
When building Distributed Software, don't fall for these assumptions.
Consensus is reached when every node agrees on the same value. The decided value must be from values that were previously proposed. Consensus is equivalent to atomic commits (atomic broadcast) [[1]]().
The reasoning around Distributed Computation can be challenging, hence the need for simplifying models. One of them is specifying the failure assumption, which can have multiple modes for process failure [[1]]().
+ Crash-stop (stop sending / receiving)
+ Omissions (leaving out information after the event)
+ Crash-recovery (process fails and restarts, and load states from backup)
+ Byzantine / arbitrary (unspecified state / messages)
+ Correct working process (sending and receiving messages)
We have adopted the crash-stop model in our work because it is very simple.
To achieve fault tolerance, Distributed Systems will have to deal with failure. By a combination of the following techniques: retrying lost packets, replicating data for availability, and replacing (changing the leader that fails). Fault tolerance is the ability to sustain operation in the face of failure.
One common use case for Distributed Systems is Sharding. In DB, it is the process of splitting a database table into multiple subsets of the table. Sharding (partitioning, replication) is organizing data into chunks that may overlap to increase availability.
Replication: duplicating of data across nodes.
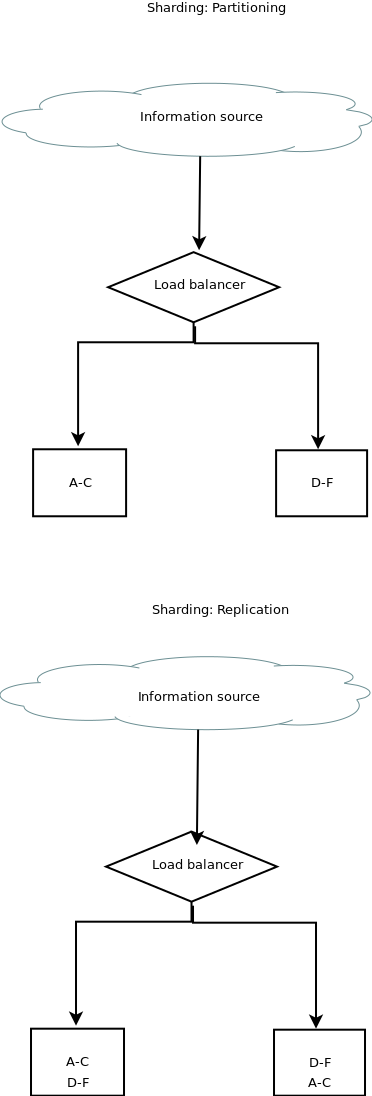
NoSQL tends to be better suited to distributed concepts such as key-value stores and document stores [[1, 7]](). There are a number of database architectures that allow for the availability of data across nodes (master-slave, master-master, buddy replication).
A replicated state machine is a way to guarantee availability in the presence of failure by mirroring the data across nodes. It has the following properties [[1]]():
+ Every replica executes every operation
+ Start state is the same as the final state
Nodes in a Distributed System can be in the following roles [[2]]():
+ Coordination: managing several nodes, e.g. leader in a Raft algorithm.
+ Cooperation: participant working together to solve a task.
+ Dissemination: replicate data to other nodes.
+ Consensus: verifying quorum and deciding on proposed values.
The prerequisite for understanding Distributed Systems is a deep understanding of network and parallel programming. We will provide a superficial treatment of both topics in the coming sections.
## Theoretical Foundations
We will discuss some theoretical foundations for Distributed Systems. They include:
+ FLP Impossibility of Consensus
+ Two general problem
### FLP Impossibility of Consensus
This describes the necessary conditions for consensus to be achieved. The following properties must hold [[1, 2, 7]]():
+ Agreement (every node must have the same value)
+ Validity (only decide on values that were previously proposed)
+ Termination (quit the algorithm after the decision has been made)
This is shown when consensus is impossible in an asynchronous, synchronous, and partially synchronous system [[1, 2, 7]]().
+ Consensus cannot be solved in an asynchronous system if there is a single failure.
+ Consensus cannot be solved in a synchronous system if N-1 nodes fail.
+ Consensus is solvable with up to N/2 crashes.
### Two general problem
Two generals have to agree at a time to launch a joint attack, and each message may receive a response. These responses are sent by messengers that can be killed at any time [[1, 2, 7]]().
Let us map to a real-world Distributed system [[1, 2, 7]]().
+ Two nodes agree on a value before a specific time-bound
+ Communication by message passing over an unreliable channel
+ Every message must be acknowledged
Two general problems imply that it is impossible to reach a consensus in asynchronous system when there is a faulty link [[1, 2, 7]]().
## Logical Clocks
If the event a occurs before the event b on the same process, then a->b where a (send) and b (deliver) occur. This relation is used to figure out happen-before relations where a global clock does not exist [[1]](). There are two major clocks which include:
+ Lamport clock
+ Vector clock
[ADD MORE INFORMATION]
Let us contrast the [differences](https://cs.stackexchange.com/questions/101496/difference-between-lamport-timestamps-and-vector-clocks) between the Lamport clock and Vector clock.
+ Lamport clock works with total order
+ Vector clock works with a partial order
Vector clock can determine if two operations are concurrent or causally dependent on each other. The Lamport clock cannot do the same.
## Paxos
This is for achieving abortable consensus in a set of nodes with the following properties [[7]]():
+ No single point of failure.
+ Accommodate network partitions
The algorithm does these steps [[1, 2]]:
+ Each node has some form of connection to every other node.
+ Only proposers can suggest values for the algorithm.
+ At consensus, every node has the same value.
The following concurrency properties include [[1, 2, 7]]():
+ Liveness: a majority must reliably communicate.
+ Safety: only proposer can suggest values.
The main characteristics of the algorithm are [[1, 2, 7]]():
+ Abortable consensus (multiple rounds may be necessary for convergence)
+ Agreement requires a quorum
There are roles that systems can take in Paxos. They include:
+ Client
+ Proposer
+ Acceptor
+ Learner
We will discuss Single-Value Paxos and Sequence Paxos in the next subsections.
### Single-Value Paxos
The algorithm does the following [[1, 2, 7]]():
+ The client sends the message to the proposer
+ Proposers send votes to the acceptors
+ Proposers accept votes from a quorum of acceptors
+ Accepted value from proposer is sent to the learner to be decided
#### Properties of Paxos algorithm [[1, 2, 7]]()
+ Validity (only proposed value can be decided)
+ Uniform agreement (no two processes decide different values)
+ Integrity (each process can decide at most one value)
+ Termination (every correct process eventually decides a value)
The version of the Single-Value Paxos algorithm implemented in this blog is shown below.
The initial states of each node in the Single-Value Paxos.

This is the sequence diagram (interaction diagram) showing showing the messages sent between different roles in the network for single value Paxos.

There are multiple variations of Single-value Paxos including fast Paxos, egalitarian Paxos, and flexible Paxos [[2]]().
### Sequence Paxos
The algorithm does as follows [[1, 2, 7]]:
+ Perform a single-valued Paxos on each item in an order.
+ Keep strict prefix as invariant
+ Maintain an ordered atomic broadcast
Consensus: an agreement in the common ordering of events across processes
make a log of decided values as repeated runs of Single-Valued Paxos algorithms
The version of the Sequence Paxos algorithm implemented in this blog is here.
The initial states of each node in the sequence Paxos

This is the sequence diagram (interaction diagram) showing the messages sent between different roles in the network for Sequence Paxos

Show the algorithm tweaks to keep the prefix invariants

## Failure Detector
A failure detector is a mechanism for identifying faults in an asynchronous system, leading to a new classification called "Timed Asynchronous system".
A Timed Asynchronous system has the following properties, including [[1]]():
+ No time-bound on message delivery
+ No time-bound on compute time
+ The clock has known drift rates
The algorithm does as follows [[1, 2, 7]]:
+ Each node has a failure detector
+ initially wrong, but eventually correct
+ periodically exchange heartbeat messages with every supposedly alive process
+ if timeout, then suspect process
+ if a message is received from a suspected node, revise suspicion, and increase the timeout.
+ Otherwise, detects a crash
consensus & atomic broadcast is solvable with a failure detector in an asynchronous system.
For a failure detector to be useful, it must meet the requirements with varying certainty [[1, 2, 7]]()
+ completeness: (when do crash nodes get detected?)
- Every crashed process is eventually detected by every correct process (liveness).
+ Accuracy: (when do alive nodes get suspected?)
- No correct process is ever suspected (safety).
These requirements can be strong or weak
We optimized for completeness instead of accuracy in our implementations. It is possible for us to suspect a healthy process, especially when there is intermittent network failure, and update its status to alive.umed that all processes are healthy at the state, it may be desirable to assume all processes are dead. It depends on what is desirable in your use case, false positive or false negative. If you are thinking of adding a timeout outside the loop of the busy-wait on reads, then you need to estimate the timeout with reference to the first message received. If you are not guaranteed to reach the first message, then we are not having a quorum in the first place.
To create a failure detector optimized for accuracy, we will take steps to prevent suspecting a healthy process. It can be helpful to increment timeout if a node does not respond to pings, rather than suspect them as failed, give a benefit of the doubt, and increase timeout with the hope that bad communication may be the culprit, rather than process failure. If we keep incrementing the timeout on a per-node basis, then we can learn the behavior of the network with time and adjust for fault connections.
Failure detectors can be improved by increasing the scope of errors that can be identified. We have a minimal subset of failures targeted in our implementation. It is desirable to use domain knowledge of the failures to expect and customize your failure detector for those kinds of situations.
## Leader Election
There are possible coordination issues when there are multipleple proposers. However, having a single proposer is easier to manage and has fewer contentions. Hence, the need to designate the leader who serves as a coordinator. Our leadership election uses a failure detector behind the hood [[1, 2, 7]]().
We are using a variation of the bully algorithm which is described here [[2]]().
The algorithm does the following:
A server can become a candidate after waiting for a set amount of time and if no other pings are received from others.ved from others. It becomes a candidate.
Note: timeout must be longer than the duration of the leader election.
The choice of delay has a significant impact on leader election.
The rule of thumb on deciding duration
+ if the value is set too low, then the second candidate begins the election before the first election triggered by the first candidate.
+ If the number is too high, it will take too long for the election to begin after the old leader has died. A new candidate starts an election.
Here is a diagram showing how leader election works
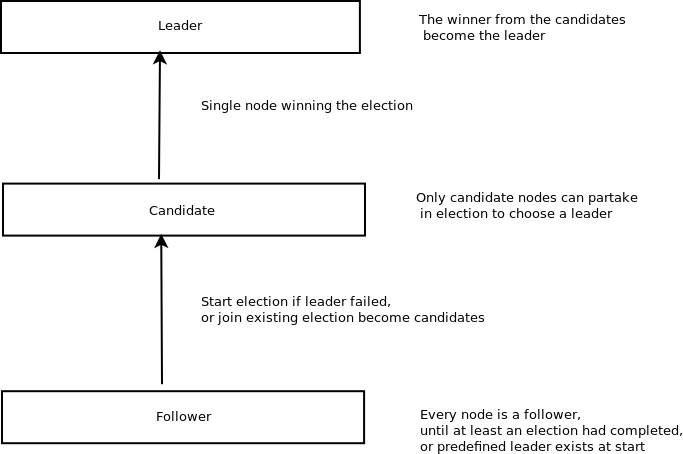
A variation using ballots for a leadership election to choose a leader from a set of candidates;
```
struct mpi_counter_t *process_cnts = create_shared_var(MPI_COMM_WORLD, 0);
inside leaderElection() function
int cnt = 0; // atomic counter
while (run_loop)
{
is_leader_dead = isLeaderFailed((*leader), msg);
if (is_leader_dead)
{
while ((end - beg) <= duration)
{
end = MPI_Wtime();
}
// see if anyone started the election as they would have updated the leader
is_leader_dead = isLeaderFailed((*leader), msg);
if (is_leader_dead)
{
printf ("A leader process has failed\n");
data package;
memset(&package, 0, sizeof(package));
// create your data here
package.ballot = (int)time(NULL);
package.pid = my_rank;
printf ("An election has been triggered\n");
beginElection (package, num_procs, requests, mpi_data_type);
}
}
// increment process using an atomic counter
cnt = increment_counter(process_cnts, 1);
if (cnt == (int) MAX(((num_procs+1) / 2.0), 1))
{
run_loop = 0;
}
}
===============================================================================
struct mpi_counter_t *process_max_ballot = create_shared_var(MPI_COMM_WORLD, 0);
struct mpi_counter_t *proc_cnts = create_shared_var(MPI_COMM_WORLD, 0);
int max_ballot = reset_var(process_max_ballot, -10000);
int cnt = 0; // atomic counter
void checkLeader (data recv, int num_procs, int leader, MPI_Request requests [], MPI_Datatype mpi_data_type, int *p_cnt)
{
int promise_cnt;
enum msgTag ctag;
data accept_value;
memset(&accept_value, 0, sizeof(accept_value));
if ((max_ballot) <= recv.ballot)
{
max_ballot = recv.ballot;
accept_value = recv;
}
cnt = increment_counter(proc_cnts, 1);
promise_cnt = (int) MAX(((num_procs+1) / 2.0), 1);
if (cnt==promise_cnt && (leader != accept_value.pid))
{
ctag = mSetLeader;
printf ("send broadcast at quorum\n");
for (int other_rank = 0; other_rank < num_procs; other_rank++)
{
MPI_Isend(&accept_value, 1, mpi_data_type, other_rank, ctag, MPI_COMM_WORLD, &requests[other_rank]);
}
}
}
Note:
Remember to reset both counters for both functions at the end of the leader election
Add the required barriers to make the example work as expected. Look at my implementation of Paxos for instructions on how to create proper atomic primitives.
```
## Raft
Paxos became complex to reason about by Software Engineers. Hence, the need to invent a simpler algorithm known as Raft. Raft is a leader election-based sequence Paxos. It consists of Paxos, log, and leader [[1, 2, 7]](). The leader is the proposer to perform coordination
A leader election is called if the leader is dead.
There are roles in the Raft algorithm
+ Candidate: node aspiring to become a leader.
+ Leader: this is the candidate who is chosen as the leader.
+ Follower: a participant that is not engaged in the election.
Possible problems:
+ Multiple leaders
+ No leaders
+ Missing log entries
+ Divergent log
Can an election choose multiple leaders [[7]]()? yes
Can an election fail to choose a leader [[7]]()? yes
In our implementation of leader election, we employed clever delay management and logic to reduce the chance of it happening in practice.
If both the answers to both questions are true, then divergent logs are likely.
In many ways, Raft is similar to leader election and sequence Paxos. Fortunately, we have implemented both, so it is very trivial to implement a Raft algorithm using a combination of both implementations. We will provide pseudocode that is similar to real source code
Using a combination of [sequence paxos](https://github.com/kenluck2001/DistributedSystemReseach/blob/master/blog/sequence-paxos4.c) and [leader election](https://github.com/kenluck2001/DistributedSystemReseach/blob/master/blog/leader-election2.c).
Algorithm 1
```
use leader election to get the leader and use as proposer
if (rank == leader)
{
// use as proposer
}
else
{
isacceptor = rank % 2 //or other forms of grouping
if (isacceptor)
{
// use as acceptor
}
else
{
// use as learner
}
}
```
Algorithm 2
Show another way of grouping to have only one acceptor.
```
use leader election to get the leader and use as proposer
if (rank == leader)
{
// use as proposer
}
else
{
islearner = (leader + 1) % n //or other forms of grouping where n: total number of processes
if (islearner)
{
// use as learner
}
else
{
// use as acceptor
}
}
```
## Implementation Philosophy for Source Code
Made use of MPI, so we do not have to deal with the low-level socket networking stacks and their quicks, between IPV4 and IPV6.
+ Our implementations in this blog make use of the crash-stop failure assumption; however, our [planned initiative](https://kenluck2001.github.io/blog_post/authoring_a_new_book_on_distributed_computing.html) will also considerzantine failure.
+ Our implementation of Distributed systems creates a set of processes for the client. This may not be standard in the Paxos algorithm. We abstract it in our source code for ease of use.
+ Our philosophy has been to think locally and act globally. We do computations on the node and communicate with other nodes by messaging.
+ Production-grade Distributed systems should follow the best Software engineering practices. We are not optimizing our source code for production, but pedagogy.
+ Rather than communicating by sharing memory, it is better to share memory by communicating.
+ For the Paxos algorithm when using Unix timestamps as the round number or ballots for their monotonically increasing properties, then a necessary prerequisite is to synchronize the time settings on at least the set of proposers, or across the cluster, but that may be unnecessary. This paradigm was heavily used in our implementations.
+ Organizing the processes into groups with custom communicators. This allows for targeted synchronization for grouped processes without impacting the whole processes in the application. This logic allows for precise control of a group of processes.
+ When trying to create an array of atomic counters. It is desirable to utilize an array of shared pointers, rather than an array of shared values.
+ We can cancel pending requests and tune the quorum threshold based on business needs. This would impact the resilience of the Distributed Systems.
+ We use pooling on receiving the message and checking each tag, rather than waiting on specific tags to make code modular. With my quest to work on a lower level, rather than use C++, I tried object-oriented design in C to enhance modularity but abandoned the [idea](https://stackoverflow.com/questions/351733/how-would-one-write-object-oriented-code-in-c) due to loss of type safety.
+ Always pool on waiting reads in a busy-wait style.
+ Make use of simple structure. Even our log for sequence Paxos is not a log, but an abused linked list with some atomic primitives.
+ Our Sequence Paxos uses a Single-Value Paxos on each item that the proposer will send. Unfortunately, our logic only allows the possibility of having one proposer.
+ Retrieving messages and probing their tags to identify specific events. Busy waiting is used to retrieve messages on an irecv. Otherwise, only the last message sent is received on polling. This can be a bug where you retrieve the same message multiple times.
+ It is good to take steps to avoid both deadlocks and livelock.
Deadlock can happen when messages are not sent in the correct order between send and receive especially in blocking mode. It is possible in non-blocking mode to consider how request objects are owned between the receiving and sending nodes.
+ Livelock is also possible when we pull busy waits in a non-blocking manner. As we exit from the end of the loop when we have received the expected number of messages. It can be sensible to keep track of the number of exchanged messages to force an exit from the endless loop.
+ There are problems with passing pointers across nodes. This is because we don't have a universal shared memory. Always keep pointers local as a lack of distributed memory makes indirection on a pointer useless.
### Random Sample of Source Codes
+ [lamport1-majority-voting5.c](https://github.com/kenluck2001/DistributedSystemReseach/blob/master/playground/lamport1-majority-voting5.c)
- A single node sends a message to every other node and receives acknowledgments from them.
+ [lamport1-majority-voting6.c](https://github.com/kenluck2001/DistributedSystemReseach/blob/master/playground/lamport1-majority-voting6.c)
- Similar to lamport1-majority-voting5.c
- Use as a base for key-value pair.
+ [lamport1-majority-voting7.c](https://github.com/kenluck2001/DistributedSystemReseach/blob/master/playground/lamport1-majority-voting7.c)
- Hashmap with fault tolerance
- Reduce the number of messages to a quorum.
+ [lamport1-majority-voting8.c](https://github.com/kenluck2001/DistributedSystemReseach/blob/master/playground/lamport1-majority-voting8.c)
- implemented key-value map
+ [single-paxos3.c](https://github.com/kenluck2001/DistributedSystemReseach/blob/master/blog/single-paxos3.c)
- Working single value Paxos
- We have an enum of client, proposer, acceptor, learner
- A missing feature that is easy to add is to propagate the decided value to every healthy node. It is very trivial and hence left out of the implementation.
+ [single-paxos5.c](https://github.com/kenluck2001/DistributedSystemReseach/blob/master/playground/single-paxos5.c)
- Limitations for using mode as an opp for MPI_Accumulate.
- It fails because the mode allocates itself too much memory, leading to an overflow.
+ [sequence-paxos.c](https://github.com/kenluck2001/DistributedSystemReseach/blob/master/playground/sequence-paxos.c)
- Introduced reset_var method has been used to reset values on a custom shared primitive
+ [failure-detector2.c](https://github.com/kenluck2001/DistributedSystemReseach/blob/master/blog/failure-detector2.c)
- This implementation ignores the use of sleep, which seems to block every process (this claim has to be verified). Instead, we are using busy waits that can only impact a thread, rather than every thread on the stack.
- Sleep gives compilation error even though I am not in strict mode. Blocking every process is not desirable for my use case, busy-wait does useless work, but is a better compromise for my use case.
+ [failure-detector.c](https://github.com/kenluck2001/DistributedSystemReseach/blob/master/playground/failure-detector.c)
- Every thread state in the array is set to 0 which denotes a healthy process. If a process is suspected to be dead, we set it to 1. However, if it comes back up or experiences network delays, we reset it to 0.
Every process has access to the array variable that decides if a process is healthy.
+ [leader-election2.c](https://github.com/kenluck2001/DistributedSystemReseach/blob/master/blog/leader-election2.c)
- This is a simplified version of our adaptation of the bully algorithm, where the first candidate becomes the node to call an election and choose itself. The rationale is that if the client can start an election, then it is alive.
## Anti-entropy Techniques
Entropy is a measure of discordance between multiple states across nodes.
Sometimes, even after running your consensus algorithm and terminating, some nodes may be off-sync. There are ways to mitigate these issues and force an agreement. I loosely see it as "secondary consensus" after the "primary consensus" has failed, or eventual consistency taking a long time for updates to be effected.
This can be the secret source of why some distributed software would work better than others. We will focus on open content and provide the general framework for reasoning about it.
One basic way to achieve it is to have a background process to check for off-sync and trigger retries to get missing data or use error correction techniques to repair the missing data and achieve conflict resolution. The easiest conflict resolution is to request data from neighbors and update the current node on retries. There are examples such as read repair and hinted backoff.
Gossip protocol: it can be used as an anti-entropy mechanism [[2]](). This is a probabilistic form of message propagation in a network using the concept of how [rumors spread in a network](https://kenluck2001.github.io/blog_post/fake_news_an_exploratory_dive_into_ways_to_identify_misinformation_in_a_network.html). In spite of significant network interruptions, the gossip algorithm is fault-tolerant. We have described the epidemic approach, but it can be done with non-epidemic approaches (overlay networks, partial views) too.
CRDT: it is an anti-entropy mechanism. Riak pioneered the use of CRDT [[2, 12]](). This is a data structure that maintains a consistent state independent of the order of operations executed on it.
Remote syncing (replication) across multiple devices can be challenging to achieve.
Mathematically, it is a partially ordered monoid forming a lattice. It has to be commutative and idempotent.
+ Eventual consistency
+ Preserve ordering of the data
+ Local-first application
Here are some kinds of CRDT which include: map (LWW-mAP), set (G-set), and others [[2, 12]]().
Ancilliary structure: These are data structures can we can use to verify if the state in the nodes is in disagreement. Ancillary structures like the Merkle tree can be used to identify and resolve conflict. Merkle tree is used for hashing a structure in a tree with the following use. We can identify disagreement among nodes if they fail the [audit or consistency proofs](https://sites.google.com/site/certificatetransparency/log-proofs-work ). Let us describe the proofs.
audit proof: verify a single chunk exists in a tree
consistency proof: compares the version of the same tree
Consistency verification
+ Data verification
+ Data synchronization
My understanding of how the Merkle tree works are that it can help to identify conflicts. One approach will be to send the hash of the data as metadata that can be used to audit the received message. Once there is a match, then we are sure the message was not corrupted. However, if the hash is a mismatch, there is a mismatch. When the data is hierarchical-like or sub-items, then it may be possible to request sub-items from neighbors to reduce transaction costs. The puzzle is that I see work that claims that the Merkle tree can resolve conflict by itself. However, my intuition is it is only possible to do so by identifying the conflict and seeking retries. Let me know of such scientific papers that do automatic conflict resolution from Merkle trees.
How conflict is resolved?
There is always a possibility that there may be a mismatch due to latency issues.
Strong consistency: every node is locked until every node is updated to a new value
Eventual consistency: This is a tradeoff in achieving consistency where every node is updated at a future time to the same value. Updates are temporarily delayed and applied in the future where the current read was the last write.
## Case Studies
### Map-reduce
key-value must be immutable.
a map function accepts a key and outputs a value.
The next operation is grouping (intermediate reduce operation)
user-specific reduce (same value have aggregated value)
map-reduce is a functional programming paradigm
```
input key-value pair
|
| map, f
|
\/
intermediate key-value pairs
|
|
|
\/
grouping
|
|
|
\/
reduce
```
Spark
key-value pair
-resilient Distributed dataset (grouping)
lazy evaluation (caching
-reducing computation grouping)
e.g. td-idf, page-rank
One possible way to approach it is to consider the problem in two cases
+ Case 1: rank 0 has all data and every other node is empty
- split the data into chunks
- mpi-scatter to send to every process (or even mpi_send). An advanced user may send to a group of users to handle intermediate nodes, where secondary reduction may be performed on a subset of nodes.
- Do computation between a subset of the node and set the result of the computation to a non-overlapping set to aggregate the result.
+ Case 2: every node already.
- skip the mpi scatter phase in case 1.
- Regroup appropriately.
The author encourages the user to implement map-reduce using the description provided in this section.
### Distributed Shared Primitive
the shared variable is protected with a lock to protect a critical section
and compare and swap can be used to update the critical section in a non-blocking manner.
I am not sure of how compare-and-swap works in mpi, my implementation of distributed shared primitive would be enhanced without blocking, which is more in line with our non-blocking approach in the source code philosophy.
if you adjust the resilience of your algorithm to enhance fault tolerance within the limit provided by quorum, then remember to cancel every outstanding request to prevent livelocks.
All of our approaches to building a Distributed shared primitive are influenced by the [work](https://stackoverflow.com/questions/4948788/creating-a-counter-that-stays-synchronized-across-mpi-processes). One of our variations of a shared variable across processes made use of one-sided communication to pass messages between processes and always select the maximum.
This works in a form of quasi-atomics and only works because our application makes use of the monotonic increasing property as an invariant. See example of commented use in [sequence-paxos3.c](https://github.com/kenluck2001/DistributedSystemReseach/blob/master/playground/sequence-paxos3.c).
```
int modify_var(struct mpi_counter_t *count, int valuein) {
int *vals = (int *)malloc( count->size * sizeof(int) );
int val;
near_atomic_shared(count, valuein, vals);
count->myval = MAX(count->myval, valuein);
vals[count->rank] = count->myval;
val = 0;
for (int i=0; isize; i++)
{
val = MAX(val, vals[i]);
}
free(vals);
return val;
}
```
Another variation is just using the latest value as the total value shared across every process. This logic makes it easier to implement a compare and swap in the future if we decide to switch to fully non-blocking. See example of use in [sequence-paxos3.c](https://github.com/kenluck2001/DistributedSystemReseach/blob/master/playground/sequence-paxos3.c).
```
int reset_var(struct mpi_counter_t *count, int valuein) {
int *vals = (int *)malloc( count->size * sizeof(int) );
int val;
near_atomic_shared(count, valuein, vals);
count->myval = valuein;
vals[count->rank] = count->myval;
val = count->myval;
free(vals);
return val;
}
```
### Distributed Hashmap
We have used the Lamport clock to make a distributed hashmap where every node has a local map (key-value pair) and in agreement, every node has the same key value key based on quorum.
# **Practical Considerations**
+ Who can partake in a leadership election? It is possible to designate nodes with permission levels. One may decide if only nodes with write permissions or read permissions can partake in the election.
+ Set an appropriate time drift for your failure detectors in accordance with specific acceptable clock drift.
+ A hybrid approach may include a centralized server to allow late joining clients to participate in the future election and get past information.
+ Set a range of rounds that a client can participate in an election
+ The number of clients that can participate in quorum using the limits of the synchronous, asynchronous, and partially synchronous.
+ It is critical to be mindful of failures and implement so form of bounded wait on the response and timeout when necessary. it can also be useful for debugging failures. Livelock can up in terminal conditions on a loop is not received to change to the terminal condition.
## Case Study: Post-mortem on triaging a distributed systems bug
The challenge arose as part of my research into building distributed systems from first principles, as documented as part of this research. Paxos is a consensus algorithm that allows multiple nodes to agree on a single value. In fact, it is arguably one of the most fundamental algorithms for building a real-world, resilient distributed system.
My task was to use the OpenMPI library to write a variant of the Paxos algorithm known as sequence Paxos. This variant would allow consensus across machines on a list of objects rather than on a single object. Due to its support for the message-passing paradigm, OpenMPI was chosen for the distributed consensus algorithm.
The problem occurred when I waited for responses from connecting nodes (to achieve a quorum) after broadcasting. The receiving node was blocked even though I was in non-blocking mode. However, I used the debugger, but it just showed the process had stopped, and there was no meaningful information. I took the OpenMPI version and started checking message boards to see if people were having similar problems. OpenMPI was popular, but nothing showed up. It is necessary to debug parallel programming on paper by writing proof to ensure there are no common failure patterns. After investigating for a few days, I noticed there was no process waiting for another process and vice versa in a typical deadlock scenario. I verified the message order to ensure that deadlocks couldn't happen, so I started looking at the termination condition in the end loop for pooling for messages from other nodes, then I realized that it was a livelock manifesting as a race condition was affecting the terminal case for the loop, there affecting retrieval for message in an endless loop.
Finally, after a week of investigation, I identified the root cause of the issue as livelock and not deadlock. I wrote a fix for the problem.
### Lessons from the project
1. When faced with a problem, don't make assumptions based on past knowledge. Treat every problem as independent. Make only assertions based on facts.
2. Prepare for unexpected delays and project overruns due to unexpected issues. Be sure that budgeting with time takes into account unforeseeable circumstances.
3. Emphasize learning from the first principles. It is time-consuming, but it helps debug problems effectively in the future.
4. Develop a complete theoretical understanding, then proceed to practical implementations, alternate as necessary. Half-baked knowledge is a recipe for disaster.
## Tips for Testing
+ Modularizing the source code and performing the unit test. Read more about the characteristics of [concurrency bugs](https://danluu.com/concurrency-bugs/) and be inspired to write unit tests.
+ Identify invariants as relations and use [metamorphic testing](https://kenluck2001.github.io/blog_post/metamorphic_testing_in_a_nutshell.html) to test with higher coverage.
+ Add assert on any conditions violations within the source code and scope within a condition flag that can be passed as a command-line argument to toggle the assertion when needed.
+ experiment on a testbed using a cluster of VMs in a LAN managed with a DevOps tool such as Vagrant, see [hints](https://github.com/mrahtz/mpi-vagrant).
# **Evaluation Metrics**
+ message complexity
- number of messages required to complete an operation
- bit complexity (message length)
+ Time complexity
- communication steps
- each communication step takes one unit.
- the time between send(m) and deliver(m) is at most one unit.
# **Exercises for the Readers**
- Write tests for the Distributed algorithm discussed in the blog. We will give the user the task OF implementing tests as an exercise.
- Implement telemetry for experimentation on characteristics of any algorithm
- Set up a testbed with a [simulated LAN with vagrant VM](https://github.com/mrahtz/mpi-vagrant) for running the mpi cluster.
- implement network shaping using VM to test out different performances in varying network bandwidths.
# **Future Work**
As part of the [upcoming textbook] (https://kenluck2001.github.io/blog_post/authoring_a_new_book_on_distributed_computing.html), we will discuss BFT and PBFT.
# **Acknowledgements**
I would like to thank professor Haridi for organizing the Reliable Distributed Algorithms (Part 1 and Part 2) course that was offered on the Edx platform a few years ago. I was not technically prepared to complete the course at the time, but I audited it after it ended.
I would like to thank Prof Vivek Sarkar whose specialization program that I took from [Coursera](https://www.coursera.org/) was named [Parallel, Concurrent, and Distributed Programming in Java Specialization](https://www.coursera.org/specializations/pcdp). He explained parallel programming and introduced me to OpenMpi, which resurrected my stalled research on distributed systems leading to this blog.
I would like to thank Anselm Eickhoff and Charles Krempeaux, who were responsive to my questions about CRDT.
I would also like to thank Harrington Joseph, who suggested that I focus on gaining a low-level understanding of parallel programming.
Some references may have been left out. Please notify the author of your concerns about missing references. I would be glad to add the reference.
# **Conclusion**
We have saved the best for last. Some topics are missing in this blog and will appear in my [new initiative](https://kenluck2001.github.io/blog_post/authoring_a_new_book_on_distributed_computing.html).). You must have noticed recurring themes in the blog, where we make abstractions. For example, our leader election uses a failure detector. Decomposing systems into components allows one to focus on a part of a problem at the time. People call it adding one more layer of indirection, it helps to reason about systems, but avoid leaky abstractions at all costs. "Most problems in Computer science can be solved with another level of abstraction".
# **References**
- [[1]]() [KTH Distributed System Course](https://e-science.se/2020/05/course-on-reliable-distributed-systems-part-i/).
- [[2]]() Database Internals: A Deep-dive into how distributed data systems work by Alex Petrov.
- [[3]]() [Beej's Guide to Unix IPC](http://beej.us/guide/bgipc/) by Brian Hall.
- [[4]]() [Beej's Guide to Network Programming Using Internet Sockets](https://beej.us/guide/bgnet/) by Brian Hall.
- [[5]]() [The Little Book of Semaphores](https://greenteapress.com/semaphores/LittleBookOfSemaphores.pdf) by Allen Downey.
- [[6]]() [Parallel, Concurrent, and Distributed Programming in Java Specialization](https://www.coursera.org/specializations/pcdp).
- [[7]]() [Summaries from MIT Distributed Systems Course](https://people.csail.mit.edu/alinush/6.824-spring-2015/index.html).
- [[8]]() [OpenMPI Examples](https://web.archive.org/web/20220305170744/https://hpc.llnl.gov/documentation/tutorials).
- [[9]]() [OpenMPI Tutorials](https://github.com/mpitutorial/mpitutorial/tree/gh-pages/tutorials).
- [[10]]() [Parallel Programming for Science and Engineering Using MPI, OpenMP, and the PETSc library](https://web.corral.tacc.utexas.edu/CompEdu/pdf/pcse/EijkhoutParallelProgramming.pdf) by Victor Eijkhout.
- [[11]]() [One-sided Communication in MPI](http://wgropp.cs.illinois.edu/courses/cs598-s15/lectures/lecture34.pdf).
- [[12]]() [List of CRDT resources](https://wiki.nikitavoloboev.xyz/distributed-systems/crdt).
# **How to Cite this Article**
```
BibTeX Citation
@article{kodoh2022,
author = {Odoh, Kenneth},
title = {Distributed Computing From First Principles},
year = {2022},
note = {https://kenluck2001.github.io/blog_post/distributed_computing_from_first_principles.html}
}
```
9/18
Please feel free to donate to support my work by clicking


