Video cards are ubiquitous in almost every commercial PC/laptop sold in the modern era, and even some mobile phones and tablets have GPUs. Why is the GPU so popular? Even [Elon Musk bought thousands of A100 GPU cards](https://www.tomshardware.com/news/elon-musk-buys-tens-of-thousands-of-gpus-for-twitter-ai-project) to build an AI lab. In the early days of video processing, GPUs were used only for display. Recently, other use cases have emerged including scientific computation, deep learning, and computational fluid mechanics.
Typically, an accelerator is connected by a message bus to the CPU. It serves as a distributed system between the main processor and these specialized hardware devices. For example, the GPU is optimized for fast matrix-based operation and can serve as a coprocessor with the main processor in the system. Accelerators optimize performance by doing heavy computation, relieving the load on the main processor by offloading specific tasks to specialized hardware. There are a few cryptographic accelerators such as [Intel Advanced Encryption Standard Instructions (AES-NI)](https://www.intel.com/content/www/us/en/developer/articles/technical/advanced-encryption-standard-instructions-aes-ni.html) for [OpenSSL](https://www.openssl.org/) and [LibreSSL](https://www.libressl.org/).
Parallel programming was a luxury in the early days of computing. However, due to the increasing capabilities of low-end computers, this skill set is essential for increasing computational performance. [Overclocking](https://en.wikipedia.org/wiki/Overclocking) was the mainstay of performance gains in the past. This has created a situation where most platforms have almost reached maximum clock speeds. GPUs on the other hand can improve performance gains by doing computation and freeing up the CPU for other tasks. A school of thought asks why do things the difficult way if you can take a shortcut and still get performance gains? Software optimization is about doing less and achieving similar performance. Parallel (concurrent) programming involves breaking a large-sized problem into smaller ones and recursively solving them. It contrasts with single-core problem-solving approaches to sequential programming. We suggest completing GPU puzzles to understand how to use GPU for problem-solving: [GPU Puzzles](https://github.com/srush/GPU-Puzzles) and [Tensor Puzzles](https://github.com/srush/Tensor-Puzzles).
My aim for learning GPU programming is to perform scientific computations and optimize post-quantum encryption routines. As part of my [Research Manifesto](https://kenluck2001.github.io/blog_post/probing_real-world_cryptosystems.html), I came across lattice methods and `"Learning with Errors"` schemes which, on superficial examination, I think may benefit from using GPU, rather than having a custom accelerator. The ideal flow is to re-structure a problem into a suitable form for GPU computation.
#### Glossary
- CPU: Central Processing Unit
- GPU: Graphical Processing Unit
- host: CPU
- device: GPU
- kernel: GPU function triggered by the host and runs on the GPU.
- A host and a device both have different memories.
# Introduction
In a typical programming paradigm (fork-join) on the CPU, we have an optimal number of threads to execute at a time. When this threshold is exceeded, performance is hit as computing is wasted on needless process communication (coordination).
GPU provides higher throughput than CPU by allowing more threads to run in parallel. Interleaving threads on a CPU are much smaller than the $\le 1024$ threads that can run at a time on a GPU without performance degradation. Hence, in summary:
- CPUs excel at sequential operations. Here is a basic CPU layout in Figure 1. It consists of instruction memory, input/output, control unit, arithmetic logic unit, and data memory.
| 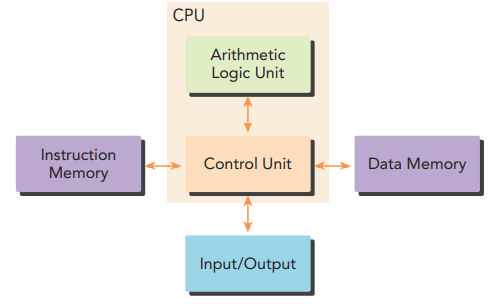 |
|:--:|
| Figure 1: CPU Architecture [[1]]() |
- GPUs excel at parallel operations. Here is a basic layout of the integration between GPU and CPU in Figure 2. This consists of a message bus (communication) between GPU and CPU, CPU component, GPU component, and several memory drives (DRAM, Cache(L1/L2)).
|  |
|:--:|
| Figure 2: GPU-CPU Co-Processor Architectures [[1]]() |
CUDA serves as a computing engine for managing GPU access. It categorizes thread groups, grids, blocks, shared memory, atomic, and barrier synchronization among others. This provides an API for structured parallelism. There are competing computing engines, including [DirectCompute](https://developer.nvidia.com/directcompute), and [OpenAcc](https://www.openacc.org/).
On the browser, GPU computing can be accessed using [WebGPU](https://www.w3.org/TR/webgpu/) with [tutorial examples](https://github.com/jack1232/webgpu01)
Blocks may be 1D, 2D, or 3D vectors of thread blocks.
Barriers are used internally to synchronize threads, grids, and blocks.
This blog will focus on [CUDA](https://en.wikipedia.org/wiki/CUDA), which supports a variety of programming languages. For example, in Python programming we have the following: [CuPy](https://docs.cupy.dev/en/stable/), [PyCuDA](https://pypi.org/project/pycuda/), and [CUDA Python](https://nvidia.github.io/cuda-python/overview.html). CUDA provides an accessible means to access the GPU, unlike building a custom accelerator. CUDA has two APIs: the Driver API and the Runtime API. It should be noted that both APIs cannot be combined at once in the same program.
#### Structure of the CUDA program [[2]]()
- Copy data from host to device
- Run kernel in GPU
- Copy the results back from the device to the host.
# Practical Considerations
- Ensure that the threads per block are multiples of 32. This is because we strive to minimize warp divergence, as a warp has 32 threads. The total number of threads in use, $n$, and the warp size, $W_{s}$ is
\begin{equation}
W_{s} = \lceil \frac{n}{32} \rceil
\end{equation}
- Avoid using smaller-sized thread blocks. The choice of block size (>= 128 or 256 threads per block)
- It does not matter if it is a row/column major, you just need to structure your CUDA program using the hierarchy of grids, blocks, and threads. CUDA programming challenges are indexing and synchronization when developing your source code.
Initialization of a kernel in CUDA requires two arguments, $blocksPerGrid$, and $threadsPerBlock$. The total number of active threads is the product of both quantities, as shown
$totalNumberOfLaunchedThreads = blocksPerGrid * threadsPerBlock$
Here is a basic layout of the GPU core in `Figure 3` which consists of grids, blocks, and threads
| 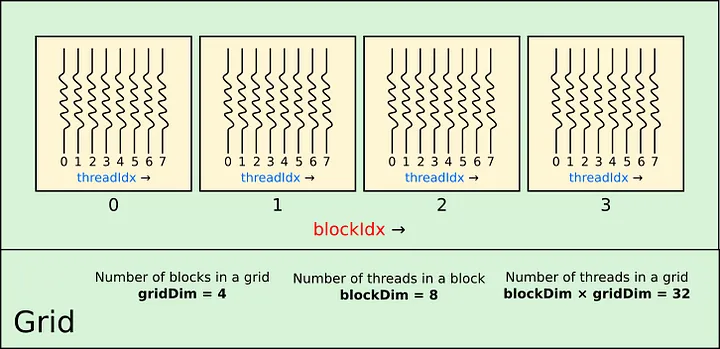 |
|:--:|
| Figure 3: [CUDA Hierarchy](https://towardsdatascience.com/cuda-by-numba-examples-1-4-e0d06651612f) Credit: Carlos Costa, Ph.D.|
- Do not perform unnecessary memory copies from the device to the host and vice-versa. There is a concept of unified memory that supports zero-copy. This uses a mapped drive for the host and devices' memory.
- CUDA Kernel functions cannot return a value, but instead return a reference via arguments.
- It is possible to use atomic operations in non-blocking modes, such as compare-and-swap when contention is low.
# Performance Evaluation
GPU performance is influenced by core count and (device, host) memory sizes. NVIDIA GPU architecture is based on a [Streaming Multiprocessor](https://stackoverflow.com/questions/3519598/streaming-multiprocessors-blocks-and-threads-cuda) (SM). There are 32 threads in a warp, which is the smallest grouping of threads that can be run on an SM.
Here is a basic layout of the warp in the GPU core as shown in `Figure 4`.
| 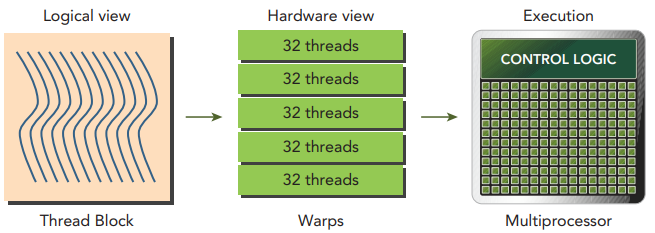 |
|:--:|
| Figure 4: Structure of the Warp [[1]]() |
Here are some performance evaluation metrics:
- Warp Divergence
- Occupancy Rate
#### Warp Divergence
The GPU lacks a complex branching mechanism. In contrast, the CPU has branching as a core feature. Branch prediction is the core of CPU branching, and branch misses are tolerated. Threads in a warp must execute identical operations during each instruction cycle. When there is a conditional within a warp, different threads can run different operations at the same time.
SM favors identical operations within a warp as other unused threads are disabled, reducing performance. Here is a case where wrap divergence can be high. We split data into even or odd threads within a kernel. This can lead to divergence as some threads are inactive within a warp. On the contrary, we could use 'warp size` to offset the indexing and run even threads in one warp and odd threads in another warp. This metric is typically captured using the 'branch efficiency' metric.
#### Occupancy Rate
This metric measures how many GPU cores are used for computation. It evaluates GPU computation efficiency. It is desirable to use as many cores as possible. The ideal configuration is to fully utilize the GPU's warp capability, rather than underutilize it. The occupancy rate, $O_{r}$, number of active warps, $n_{a}$, and total number of warps on the GPU, $n$.
\begin{equation}
O_{r} = \lceil \frac{n_{a}}{n} \rceil
\end{equation}
# Conclusions
- GPU programming may require a parallel programming mindset.
- Underutilizing hardware potential for increased computational performance is a missed opportunity. Most user-end computers support graphic cards, which boost computationally-heavy tasks. Hence, it is imperative to use these GPUs to speed up computational processing speeds in these consumer devices.
# References
- [[1]]() Professional CUDA C Programming by John Cheng, Max Grossman, and Ty McKercher, John Wiley & Sons, Inc. 2014.
- [[2]]() CUDA by Example: An introduction to general-purpose GPU programming by Jason Sanders, Edward Kandrot, Addison-Wesley, 2011.
5/18
Please feel free to donate to support my work by clicking


